
Die Teilung, die niemand erwartet hat
Unsere Forschung stellte vom 6. bis 20. Oktober 2025 jeden Tag 10 Fahrradfragen. Das sind 100 Datenanfragen pro Abfrage und Tag.
Einige Fragen führten zu null Websuchen. Überhaupt nicht.
"In welchem Alter sollte ein Kind lernen, Fahrrad zu fahren?" hatte an allen 15 Tagen eine Suchwahrscheinlichkeit von 0%. ChatGPT behandelt dies als festes Wissen. Keine Validierung erforderlich.
Das ist in Ordnung und das war zu erwarten.
Schauen Sie sich jetzt das hier an: "Was ist das sicherste Fahrrad für ein Kind, das gerade gelernt hat, ohne Stützräder zu fahren?" Diese Frage sprang in fünf Tagen von 40% Suchwahrscheinlichkeit auf 19%.
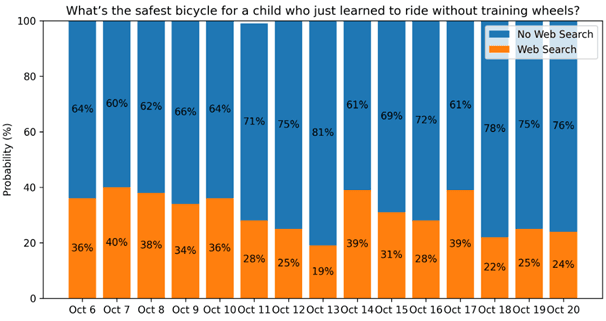
Sicherheitsfragen? An einem Tag fühlt sich die KI sicher. Am nächsten Tag sucht sie im Internet nach Antworten. Wenn Sie den KI-Kundenservice für einen E-Commerce-Shop betreiben, könnte dies ein operationelles Risiko darstellen.
Die 50%-Deckelung
Unser Hauptbefund: Keine Frage hatte im Durchschnitt eine Suchwahrscheinlichkeit von über 50%.
ChatGPT greift standardmäßig auf internes Wissen für Produktanleitungen zurück. Es sucht nur, wenn das Vertrauen sinkt. Aber selbst dann bleibt es unter 50%. Das deutet darauf hin, dass das Modell eingebaute Sicherheitsvorkehrungen hat. Vielleicht, um eine Überabhängigkeit von externen Daten zu verhindern. Vielleicht, um Kosten zu steuern.
Wir werden es nie erfahren.
Produktvergleichsanfragen zeigten moderate Schwankungen. "Was ist der Unterschied zwischen einem 20-Zoll- und einem 24-Zoll-Fahrrad für Kinder?" Hier würde man Stabilität erwarten. Das sind Maße, keine Meinungen. Aber die Suchwahrscheinlichkeit variierte trotzdem.
Das Modell behandelt alterspezifische Empfehlungen unterschiedlich nach Kohorte. Eine Fahrradfrage eines siebenjährigen Kindes verhält sich anders als die eines fünfjährigen. Und es gibt kein Muster, das wir erkennen können.
Wenn Stabilität über Nacht volatil wird
Hier wird es interessant.
"Was ist die ideale Fahrradgröße für ein siebenjähriges Mädchen?" zeigte 11 Tage lang eine Suchwahrscheinlichkeit von 0%. Vorhersehbar. Nur internes Wissen.
Dann sprang es am 17. Oktober auf 32%. Und blieb dort.
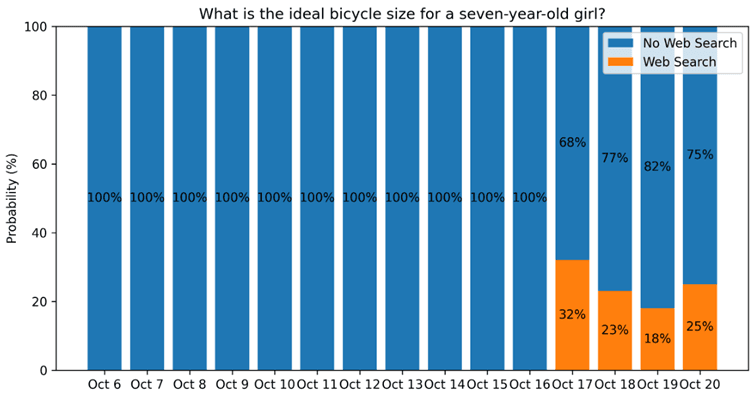
Wir haben kein Modell-Update gesehen. Keine Erklärung.
Wenn Sie die KI-Leistung monatlich überwachen, haben Sie es verpasst. Wenn Sie überhaupt nicht überwachen, wissen Sie nicht einmal, dass es passiert ist.
Markenbewertungsanfragen zeigten ähnliche Volatilität. "Ist diese Marke es wert, Abus Smiley 3.0 zu kaufen?" schwankte zwischen 22% und 47% Suchwahrscheinlichkeit. Ihr Produkt wird am Dienstag anders empfohlen als am Montag.
Die Variablen, die wir nicht sehen können
Die Forschung fand Muster, aber keine Ursachen.
Warum behält eine Abfrage 100% Stabilität, während ähnliche Abfragen wild schwanken? Warum ändern sich Wahrscheinlichkeiten an bestimmten Daten? Was löst diese Veränderungen aus?
Diese blinden Flecken schaffen Probleme für E-Commerce-Teams. Sie können nicht vorhersagen, wann KI-Tools von internem Wissen zu Websuchen wechseln. Das beeinflusst die Reaktionsgeschwindigkeit und die Konsistenz der Empfehlungen.
Überwachung ist nicht mehr optional
Dieses 11-tägige Plateau, gefolgt von einem plötzlichen Wechsel? Das ist der Grund, warum punktuelle Audits nicht funktionieren.
Sie benötigen kontinuierliche Überwachungssysteme, die verfolgen, wann und wie oft Ihre Produktkategorien Websuchen auslösen. Veränderungen im Suchverhalten signalisieren Verschiebungen im KI-Vertrauen, veränderte Trainingsgewichte oder modifizierte Kostenparameter. All dies beeinflusst das Kundenerlebnis.
Was tun Sie also?
Produktkategorien mit hoher Volatilität benötigen besondere Aufmerksamkeit. Schutzausrüstung. Markenbewertungen. Diese könnten von benutzerdefinierten Trainingsdaten, expliziten Produktfeeds oder hybriden Ansätzen profitieren, die KI-Antworten mit strukturierten Produktdatenbanken kombinieren.
Das Ziel? Konsistenz unabhängig von Schwankungen im Suchverhalten.
Die eigentliche Frage
Es geht nicht darum, ob KI das Verhalten ändert. Es geht darum, ob Sie überwachen, wann es das tut.
Diese Forschung umfasst 15 Tage von Fahrradabfragen. Ein Bereich. Ein Zeitraum. Ein Modell. Aber die Muster deuten auf breitere Implikationen für jeden hin, der KI im E-Commerce einsetzt.
Die 50%-Deckelung. Das Wendepunktverhalten. Die kategoriespezifische Volatilität. Das sind keine Fehler. Es sind Merkmale von Systemen, die unter Bedingungen arbeiten, die wir nicht sehen können.
Also überwachen Sie aktiv. Testen Sie kontinuierlich. Schaffen Sie Redundanz, wo die Volatilität hoch ist.